An introduction to RL with SheepRL: the A2C algorithm
What is Reinforcement Learning?
Reinforcement Learning (RL) is a branch of Machine Learning that deals with the problem of learning from experience, i.e. “RL is learning what to do - how to map situations to actions - so to maximize a numerical reward signal. The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.” (Richard S. Sutton and Andrew G. Barto, Reinforcement Learning: An Introduction, 2018). Those actions may not only affect the immediate reward but also the next ones and, through that, all subsequent rewards. These two concepts, trial-and-error and delayed reward, are the two most important distinguishing features of RL, setting it apart from other form of learning, in fact:
- RL is different from supervised learning because the training data is not given in the form of input-output pairs, but instead, the agent must discover which actions yield the most reward by trying them
- RL is different from unsupervised learning, which is tipically used to uncover hidden structures in unlabeled data, even though one may think of the former as an instance of the latter since RL does not rely on labelled examples of correct behaviour
This informal idea of the agent’s goal being to maximize the total amount of reward it receives is called reward hypothesis:
That all of what we mean by goals and purposes can be well thought of as the maximization of the expected value of the cumulative sum of a received scalar signal (called reward).
RL at a high-level
At a high-level RL can be summarized by the following figure:
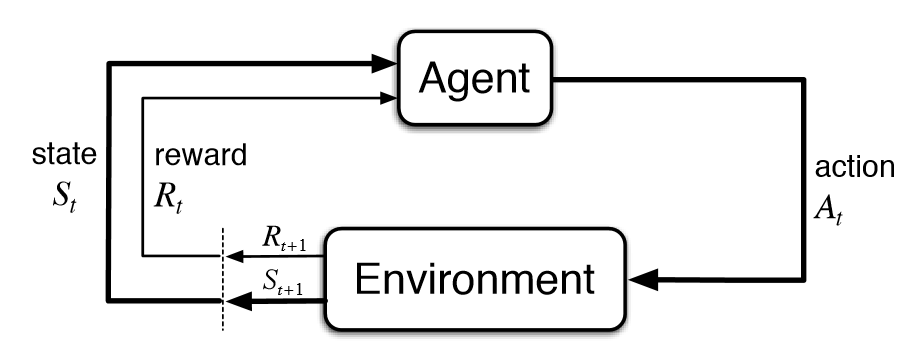
where the main components are:
- Agent: the one that behaves in the environment and learns from experiences gathered through the repeated interactions with it
- Environment: the world (physical or virtual) where the agent lives and acts
- State: a representation of the environment at a particular point in time, used by the agent to base its decisions
- Reward: a numerical value that represents whether the action $A_t$ taken at time $t$ in state $S_t$, resulting in the state $S_{t+1}$, was a good or bad choice
The agent and the environment interact with each other in a sequence of discrete time steps, $t=0,1,2,3,…$. At each time step $t$, the agent receives a representation of the environment’s state, $S_t \in \mathcal{S}$, where $\mathcal{S}$ is the set of all possible states. Based on that, the agent selects an action, $A_t \in \mathcal{A}(S_t)$, where $\mathcal{A}(S_t)$ is the set of all possible actions in state $S_t$. One time step later, the agent receives a numerical reward, $R_{t+1} \in \mathcal{R} \subset \mathbb{R}$, and finds the environment in a new state, $S_{t+1}$, changed given the previous agent’s action.
The main objective of the agent is to maximize the expected reward over the long run, i.e. to maximize the expected sum of the rewards it receives from the beginning to the end of the (possibly never-ending) episode, $T$ ($\infty$). The expected sum of rewards is called return and it is defined as:
\[G = R_{1} + R_{2} + R_{3} + ... = \sum_{k=0}^{\infty} R_{k+1}\]In practice, the reward $R_t$ received at time $t$ is often discounted by a factor $\gamma \in (0,1)$, where $\gamma$ is called discount rate (or discount factor), i.e.:
\[G = R_{1} + \gamma R_{2} + \gamma^2 R_{3} + ... = \sum_{k=0}^{\infty} \gamma^{k} R_{k+1}\]This is useful for at least two reasons:
- It allows to make the sum of rewards finite even if the episode is infinite. In fact, if we suppose to have an infinite episode with a constant reward $R_t = r \ll \infty$, then the return would be infinite as well. By discounting the reward, the return becomes: \(G = r + \gamma r + \gamma^2 r + ... = \sum_{k=0}^{\infty} \gamma^{k} r = \frac{r}{1-\gamma}\)
- It allows to choose how much importance is given to immediate rewards vs future rewards: the higher the discount rate, the more the agent will care about future rewards; the lower the discount rate, the more the agent will care about immediate rewards instead
RL at a low-level
At a low-level (i.e. mathematically), RL can be described by the following:
- The set of possible states $\mathcal{S}$, where $S_t \in \mathcal{S}$ is the state of the environment at time $t$
- The set of possible actions $\mathcal{A}$, where $A_t \in \mathcal{A}$ is the action taken by the agent at time $t$, given the environment state $S_t$
- The transition function $\mathcal{P}$, where \(p(s'\vert s,a) : \mathcal{S} \times \mathcal{A} \times \mathcal{S} \rightarrow \left[0,1\right] = \mathbb{P}\left[S_{t+1} = s' \vert S_t = s, A_t = a \right]\) is the probability of transitioning to state $s’$ at time $t+1$ given that the agent is in state $s$ at time $t$ and takes action $a$ at time $t$
- The reward function $\mathcal{R}$, where \(r(s,a) : \mathcal{S} \times \mathcal{A} \rightarrow \left[0,1\right] = \mathbb{E}\left[ R_{t+1} \vert S_t = s, A_t = a \right]\) is the expected reward received by the agent at time $t+1$ given that the agent is in state $s$ at time $t$ and takes action $a$ at time $t$
- The policy $\pi$, where $\pi(a \vert s) : \mathcal{S} \times \mathcal{A} \rightarrow \left[0,1\right]$ is the probability of taking action $a$ at time $t$ given that the agent is in state $s$ at time $t$
The agent, interacting with the environment, generates a sequence of state-action-reward tuples, called trajectory:
\[\tau = s_0, a_0, r_1, s_1, a_1, r_2, s_2, a_2, r_3, ...\]while its goal is to maximize the expected return, averaged over all possible trajectories, i.e. find that policy $\pi$ that maximizes the expected return $\eta(\pi)$:
\[\eta(\pi) = \mathbb{E}_{s_0, a_0, r_1, ...} \left[ \sum_{t=0}^{\infty} \gamma^{t} r(s_t, a_t) \right]\]where:
- $s_0$ is a random initial environment state
- $a_t \sim \pi(a_t \vert s_t)$
- $s_{t+1} \sim p(s_{t+1} \vert s_t,a_t)$
- $r_{t+1} = r(s_t, a_t)$
RL at a practical level
In practice there are a lot of different algorithms that can be used to solve RL problems, some of them being already covered (Dreamer-V1, Dreamer-V2, Dreamer-V3, PPO, SAC and P2E). In this article we will focus on the Advantage Actor Critic (A2C) algorithm, which is a policy gradient method that uses the actor-critic architecture, composed by:
- An Actor, which takes as input the environment state $s_t$ and outputs a probability distribution over the possible actions $a_t$
- A Critic, which takes as input the environment state $s_t$ and outputs a value $V(s_t)$, which is an estimate of the expected return if the agent starts in state $s_t$ and follows the policy $\pi$ afterwards
Let’s dive in
Let’s start following what the SheepRL’s how-to guide suggests, by first installing the SheepRL package with pip install sheeprl[atari,box2d,dev,test] and then creating a new folder for our algorithm, called a2c, under which we create five new files called a2c.py, agent.py, loss.py, utils.py and the standard __init__.py:
./a2c
├── a2c.py
├── agent.py
├── __init__.py
├── loss.py
└── utils.py
1. a2c.py
The first thing we need to do is to import the necessary modules and prepare the skeleton of our algorithm. For simplicity our agent will work with only vector observations, so we need to check that no images will be returned by the environment:
# a2c.py
import os
import warnings
from typing import Any, Dict
import gymnasium as gym
import hydra
import numpy as np
import torch
from lightning.fabric import Fabric
from sheeprl.data import ReplayBuffer
from sheeprl.utils.env import make_env
from sheeprl.utils.logger import get_log_dir, get_logger
from sheeprl.utils.metric import MetricAggregator
from sheeprl.utils.registry import register_algorithm
from sheeprl.utils.timer import timer
from sheeprl.utils.utils import gae, save_configs
from torch.utils.data import BatchSampler, DistributedSampler, RandomSampler
from torchmetrics import SumMetric
from a2c.agent import build_agent
from a2c.loss import policy_loss, value_loss
from a2c.utils import test
def train(
fabric: Fabric,
agent: torch.nn.Module,
optimizer: torch.optim.Optimizer,
data: Dict[str, torch.Tensor],
aggregator: MetricAggregator,
cfg: Dict[str, Any],
):
"""Train the agent on the data collected from the environment."""
# Prepare the sampler
# If we are in the distributed setting, we need to use a DistributedSampler, which
# will shuffle the data at each epoch and will ensure that each process will get
# a different part of the data
indexes = list(range(next(iter(data.values())).shape[0]))
if cfg.buffer.share_data:
sampler = DistributedSampler(
indexes,
num_replicas=fabric.world_size,
rank=fabric.global_rank,
shuffle=True,
seed=cfg.seed,
)
else:
sampler = RandomSampler(indexes)
sampler = BatchSampler(sampler, batch_size=cfg.algo.per_rank_batch_size, drop_last=False)
optimizer.zero_grad(set_to_none=True)
if cfg.buffer.share_data:
sampler.sampler.set_epoch(0)
# Train the agent
# Even though in the Spinning-Up A2C algorithm implementation
# (https://spinningup.openai.com/en/latest/algorithms/vpg.html) the policy gradient is estimated
# by taking the mean over all the sequences collected
# of the sum of the actions log-probabilities gradients' multiplied by the advantages,
# we do not do that, instead we take the overall sum (or mean, depending on the loss reduction).
# This is achieved by accumulating the gradients and calling the backward method only at the end.
for i, batch_idxes in enumerate(sampler):
batch = {k: v[batch_idxes] for k, v in data.items()}
obs = {k: batch[k] for k in cfg.algo.mlp_keys.encoder}
# is_accumulating is True for every i except for the last one
is_accumulating = i < len(sampler) - 1
with fabric.no_backward_sync(agent, enabled=is_accumulating):
_, logprobs, values = agent(obs, torch.split(batch["actions"], agent.actions_dim, dim=-1))
# Policy loss
pg_loss = policy_loss(
logprobs,
batch["advantages"],
cfg.algo.loss_reduction,
)
# Value loss
v_loss = value_loss(
values,
batch["returns"],
cfg.algo.loss_reduction,
)
loss = pg_loss + v_loss
fabric.backward(loss)
if not is_accumulating:
if cfg.algo.max_grad_norm > 0.0:
fabric.clip_gradients(agent, optimizer, max_norm=cfg.algo.max_grad_norm)
optimizer.step()
# Update metrics
if aggregator and not aggregator.disabled:
aggregator.update("Loss/policy_loss", pg_loss.detach())
aggregator.update("Loss/value_loss", v_loss.detach())
@register_algorithm(decoupled=False)
def main(fabric: Fabric, cfg: Dict[str, Any]):
rank = fabric.global_rank
world_size = fabric.world_size
device = fabric.device
fabric.seed_everything(cfg.seed)
# Resume from checkpoint
if cfg.checkpoint.resume_from:
state = fabric.load(cfg.checkpoint.resume_from)
# Create Logger. This will create the logger only on the
# rank-0 process
logger = get_logger(fabric, cfg)
if logger and fabric.is_global_zero:
fabric._loggers = [logger]
fabric.logger.log_hyperparams(cfg)
log_dir = get_log_dir(fabric, cfg.root_dir, cfg.run_name)
fabric.print(f"Log dir: {log_dir}")
# Environment setup
vectorized_env = gym.vector.SyncVectorEnv if cfg.env.sync_env else gym.vector.AsyncVectorEnv
envs = vectorized_env(
[
make_env(
cfg,
cfg.seed + rank * cfg.env.num_envs + i,
rank * cfg.env.num_envs,
log_dir if rank == 0 else None,
"train",
vector_env_idx=i,
)
for i in range(cfg.env.num_envs)
]
)
observation_space = envs.single_observation_space
if not isinstance(observation_space, gym.spaces.Dict):
raise RuntimeError(f"Unexpected observation type, should be of type Dict, got: {observation_space}")
if len(cfg.algo.mlp_keys.encoder) == 0:
raise RuntimeError("You should specify at least one MLP key for the encoder: `algo.mlp_keys.encoder=[state]`")
for k in cfg.algo.mlp_keys.encoder + cfg.algo.cnn_keys.encoder:
if k in observation_space.keys() and len(observation_space[k].shape) > 1:
raise ValueError(
"Only environments with vector-only observations are supported by the A2C agent. "
f"The observation with key '{k}' has shape {observation_space[k].shape}. "
f"Provided environment: {cfg.env.id}"
)
if cfg.metric.log_level > 0:
fabric.print("Encoder CNN keys:", cfg.algo.cnn_keys.encoder)
fabric.print("Encoder MLP keys:", cfg.algo.mlp_keys.encoder)
if len(cfg.algo.cnn_keys.encoder) > 0:
warnings.warn("The A2C agent does not support pixel-based observations, the CNN keys will be ignored.")
cfg.algo.cnn_keys.encoder = []
obs_keys = cfg.algo.cnn_keys.encoder + cfg.algo.mlp_keys.encoder
is_continuous = isinstance(envs.single_action_space, gym.spaces.Box)
is_multidiscrete = isinstance(envs.single_action_space, gym.spaces.MultiDiscrete)
actions_dim = tuple(
envs.single_action_space.shape
if is_continuous
else (envs.single_action_space.nvec.tolist() if is_multidiscrete else [envs.single_action_space.n])
)
# Create the actor and critic models
agent = build_agent(
fabric,
actions_dim,
is_continuous,
cfg,
observation_space,
state["agent"] if cfg.checkpoint.resume_from else None,
)
# Define the optimizer
optimizer = hydra.utils.instantiate(cfg.algo.optimizer, params=agent.parameters(), _convert_="all")
if fabric.is_global_zero:
save_configs(cfg, log_dir)
# Load the state from the checkpoint
if cfg.checkpoint.resume_from:
optimizer.load_state_dict(state["optimizer"])
# Setup agent and optimizer with Fabric
optimizer = fabric.setup_optimizers(optimizer)
# Create a metric aggregator to log the metrics
aggregator = None
if not MetricAggregator.disabled:
aggregator: MetricAggregator = hydra.utils.instantiate(cfg.metric.aggregator, _convert_="all").to(device)
# Local data
if cfg.buffer.size < cfg.algo.rollout_steps:
raise ValueError(
f"The size of the buffer ({cfg.buffer.size}) cannot be lower "
f"than the rollout steps ({cfg.algo.rollout_steps})"
)
rb = ReplayBuffer(
cfg.buffer.size,
cfg.env.num_envs,
memmap=cfg.buffer.memmap,
memmap_dir=os.path.join(log_dir, "memmap_buffer", f"rank_{fabric.global_rank}"),
obs_keys=obs_keys,
)
# Global variables
last_train = 0
train_step = 0
start_step = (
# + 1 because the checkpoint is at the end of the update step
# (when resuming from a checkpoint, the update at the checkpoint
# is ended and you have to start with the next one)
(state["update"] // fabric.world_size) + 1
if cfg.checkpoint.resume_from
else 1
)
policy_step = state["update"] * cfg.env.num_envs * cfg.algo.rollout_steps if cfg.checkpoint.resume_from else 0
last_log = state["last_log"] if cfg.checkpoint.resume_from else 0
last_checkpoint = state["last_checkpoint"] if cfg.checkpoint.resume_from else 0
policy_steps_per_update = int(cfg.env.num_envs * cfg.algo.rollout_steps * world_size)
num_updates = cfg.algo.total_steps // policy_steps_per_update if not cfg.dry_run else 1
if cfg.checkpoint.resume_from:
cfg.algo.per_rank_batch_size = state["batch_size"] // fabric.world_size
# Warning for log and checkpoint every
if cfg.metric.log_level > 0 and cfg.metric.log_every % policy_steps_per_update != 0:
warnings.warn(
f"The metric.log_every parameter ({cfg.metric.log_every}) is not a multiple of the "
f"policy_steps_per_update value ({policy_steps_per_update}), so "
"the metrics will be logged at the nearest greater multiple of the "
"policy_steps_per_update value."
)
if cfg.checkpoint.every % policy_steps_per_update != 0:
warnings.warn(
f"The checkpoint.every parameter ({cfg.checkpoint.every}) is not a multiple of the "
f"policy_steps_per_update value ({policy_steps_per_update}), so "
"the checkpoint will be saved at the nearest greater multiple of the "
"policy_steps_per_update value."
)
# Get the first environment observation and start the optimization
step_data = {}
next_obs = envs.reset(seed=cfg.seed)[0] # [N_envs, N_obs]
for k in obs_keys:
step_data[k] = next_obs[k][np.newaxis]
for update in range(start_step, num_updates + 1):
for _ in range(0, cfg.algo.rollout_steps):
policy_step += cfg.env.num_envs * world_size
# Measure environment interaction time: this considers both the model forward
# to get the action given the observation and the time taken into the environment
with timer("Time/env_interaction_time", SumMetric(sync_on_compute=False)):
with torch.no_grad():
# Sample an action given the observation received by the environment
torch_obs = {k: torch.as_tensor(next_obs[k], dtype=torch.float32, device=device) for k in obs_keys}
actions, _, values = agent.module(torch_obs)
if is_continuous:
real_actions = torch.cat(actions, -1).cpu().numpy()
else:
real_actions = torch.cat([act.argmax(dim=-1) for act in actions], dim=-1).cpu().numpy()
actions = torch.cat(actions, -1).cpu().numpy()
# Single environment step
obs, rewards, dones, truncated, info = envs.step(real_actions.reshape(envs.action_space.shape))
dones = np.logical_or(dones, truncated).reshape(cfg.env.num_envs, -1).astype(np.uint8)
rewards = rewards.reshape(cfg.env.num_envs, -1)
# Update the step data
step_data["dones"] = dones[np.newaxis]
step_data["values"] = values.cpu().numpy()[np.newaxis]
step_data["actions"] = actions[np.newaxis]
step_data["rewards"] = rewards[np.newaxis]
if cfg.buffer.memmap:
step_data["returns"] = np.zeros_like(rewards, shape=(1, *rewards.shape))
step_data["advantages"] = np.zeros_like(rewards, shape=(1, *rewards.shape))
# Append data to buffer
rb.add(step_data, validate_args=cfg.buffer.validate_args)
# Update the observation and dones
next_obs = obs
for k in obs_keys:
step_data[k] = obs[k][np.newaxis]
if cfg.metric.log_level > 0 and "final_info" in info:
for i, agent_ep_info in enumerate(info["final_info"]):
if agent_ep_info is not None:
ep_rew = agent_ep_info["episode"]["r"]
ep_len = agent_ep_info["episode"]["l"]
if aggregator and "Rewards/rew_avg" in aggregator:
aggregator.update("Rewards/rew_avg", ep_rew)
if aggregator and "Game/ep_len_avg" in aggregator:
aggregator.update("Game/ep_len_avg", ep_len)
fabric.print(f"Rank-0: policy_step={policy_step}, reward_env_{i}={ep_rew[-1]}")
# Transform the data into PyTorch Tensors
local_data = rb.to_tensor(dtype=None, device=device, from_numpy=cfg.buffer.from_numpy)
# Estimate returns with GAE (https://arxiv.org/abs/1506.02438)
with torch.no_grad():
torch_obs = {k: torch.as_tensor(next_obs[k], dtype=torch.float32, device=device) for k in obs_keys}
next_values = agent.module.get_value(torch_obs)
returns, advantages = gae(
local_data["rewards"].to(torch.float64),
local_data["values"],
local_data["dones"],
next_values,
cfg.algo.rollout_steps,
cfg.algo.gamma,
cfg.algo.gae_lambda,
)
# Add returns and advantages to the buffer
local_data["returns"] = returns.float()
local_data["advantages"] = advantages.float()
if cfg.buffer.share_data and fabric.world_size > 1:
# Gather all the tensors from all the world and reshape them
gathered_data: Dict[str, torch.Tensor] = fabric.all_gather(local_data)
# Flatten the first three dimensions: [World_Size, Buffer_Size, Num_Envs]
gathered_data = {k: v.flatten(start_dim=0, end_dim=2).float() for k, v in gathered_data.items()}
else:
# Flatten the first two dimensions: [Buffer_Size, Num_Envs]
gathered_data = {k: v.flatten(start_dim=0, end_dim=1).float() for k, v in local_data.items()}
with timer("Time/train_time", SumMetric(sync_on_compute=cfg.metric.sync_on_compute)):
train(fabric, agent, optimizer, gathered_data, aggregator, cfg)
train_step += world_size
if cfg.metric.log_level > 0:
# Log metrics
if cfg.metric.log_level > 0 and (policy_step - last_log >= cfg.metric.log_every or update == num_updates):
# Sync distributed metrics
if aggregator and not aggregator.disabled:
metrics_dict = aggregator.compute()
fabric.log_dict(metrics_dict, policy_step)
aggregator.reset()
# Sync distributed timers
if not timer.disabled:
timer_metrics = timer.compute()
if "Time/train_time" in timer_metrics:
fabric.log(
"Time/sps_train",
(train_step - last_train) / timer_metrics["Time/train_time"],
policy_step,
)
if "Time/env_interaction_time" in timer_metrics:
fabric.log(
"Time/sps_env_interaction",
((policy_step - last_log) / world_size * cfg.env.action_repeat)
/ timer_metrics["Time/env_interaction_time"],
policy_step,
)
timer.reset()
# Reset counters
last_log = policy_step
last_train = train_step
# Checkpoint model
if (cfg.checkpoint.every > 0 and policy_step - last_checkpoint >= cfg.checkpoint.every) or (
update == num_updates and cfg.checkpoint.save_last
):
last_checkpoint = policy_step
state = {
"agent": agent.state_dict(),
"optimizer": optimizer.state_dict(),
"update": update * world_size,
"batch_size": cfg.algo.per_rank_batch_size * fabric.world_size,
"last_log": last_log,
"last_checkpoint": last_checkpoint,
}
ckpt_path = os.path.join(log_dir, f"checkpoint/ckpt_{policy_step}_{fabric.global_rank}.ckpt")
fabric.call("on_checkpoint_coupled", fabric=fabric, ckpt_path=ckpt_path, state=state)
envs.close()
if fabric.is_global_zero:
test(agent.module, fabric, cfg, log_dir)
2. agent.py
The second thing is the agent.py file, where we will define the build_agent function, which will be used to create the agent model. We can take inspiration from the PPO agent.py file and, to keep thing at a demonstration level, remove everything regarding the encoding/processing of pixel-based observations:
# agent.py
from typing import Any, Dict, List, Optional, Sequence, Tuple
import gymnasium
import torch
import torch.nn as nn
from lightning import Fabric
from lightning.fabric.wrappers import _FabricModule
from torch import Tensor
from torch.distributions import Distribution, Independent, Normal
from sheeprl.models.models import MLP
from sheeprl.utils.distribution import OneHotCategoricalValidateArgs
class MLPEncoder(nn.Module):
def __init__(
self,
input_dim: int,
features_dim: int,
keys: Sequence[str],
dense_units: int = 64,
mlp_layers: int = 2,
dense_act: nn.Module = nn.ReLU,
) -> None:
super().__init__()
self.keys = keys
self.input_dim = input_dim
self.output_dim = features_dim
self.model = MLP(
input_dim,
features_dim,
[dense_units] * mlp_layers,
activation=dense_act
)
def forward(self, obs: Dict[str, Tensor]) -> Tensor:
x = torch.cat([obs[k] for k in self.keys], dim=-1)
return self.model(x)
class A2CAgent(nn.Module):
def __init__(
self,
actions_dim: Sequence[int],
obs_space: gymnasium.spaces.Dict,
encoder_cfg: Dict[str, Any],
actor_cfg: Dict[str, Any],
critic_cfg: Dict[str, Any],
distribution_cfg: Dict[str, Any],
mlp_keys: Sequence[str],
is_continuous: bool = False,
):
super().__init__()
self.actions_dim = actions_dim
self.obs_space = obs_space
self.distribution_cfg = distribution_cfg
self.mlp_keys = mlp_keys
self.is_continuous = is_continuous
# Feature extractor
mlp_input_dim = sum([obs_space[k].shape[0] for k in mlp_keys])
self.feature_extractor = (
MLPEncoder(
mlp_input_dim,
encoder_cfg.mlp_features_dim,
mlp_keys,
encoder_cfg.dense_units,
encoder_cfg.mlp_layers,
eval(encoder_cfg.dense_act),
)
if mlp_keys is not None and len(mlp_keys) > 0
else None
)
features_dim = self.feature_extractor.output_dim
# Critic
self.critic = MLP(
input_dims=features_dim,
output_dim=1,
hidden_sizes=[critic_cfg.dense_units] * critic_cfg.mlp_layers,
activation=eval(critic_cfg.dense_act)
)
# Actor
self.actor_backbone = MLP(
input_dims=features_dim,
output_dim=None,
hidden_sizes=[actor_cfg.dense_units] * actor_cfg.mlp_layers,
activation=eval(actor_cfg.dense_act),
flatten_dim=None
)
if is_continuous:
# Output is a tuple of two elements: mean and log_std, one for every action
self.actor_heads = nn.ModuleList([nn.Linear(actor_cfg.dense_units, sum(actions_dim) * 2)])
else:
# Output is a tuple of one element: logits, one for every action
self.actor_heads = nn.ModuleList(
[nn.Linear(actor_cfg.dense_units, action_dim) for action_dim in actions_dim]
)
def forward(
self, obs: Dict[str, Tensor], actions: Optional[List[Tensor]] = None
) -> Tuple[Sequence[Tensor], Tensor, Tensor]:
feat = self.feature_extractor(obs)
out: Tensor = self.actor_backbone(feat)
pre_dist: List[Tensor] = [head(out) for head in self.actor_heads]
values = self.critic(feat)
if self.is_continuous:
mean, log_std = torch.chunk(pre_dist[0], chunks=2, dim=-1)
std = log_std.exp()
normal = Independent(
Normal(mean, std, validate_args=self.distribution_cfg.validate_args),
1,
validate_args=self.distribution_cfg.validate_args,
)
if actions is None:
actions = normal.sample()
else:
# always composed by a tuple of one element containing all the
# continuous actions
actions = actions[0]
log_prob = normal.log_prob(actions)
return tuple([actions]), log_prob.unsqueeze(dim=-1), values
else:
should_append = False
actions_logprobs: List[Tensor] = []
actions_dist: List[Distribution] = []
if actions is None:
should_append = True
actions: List[Tensor] = []
for i, logits in enumerate(pre_dist):
actions_dist.append(
OneHotCategoricalValidateArgs(
logits=logits, validate_args=self.distribution_cfg.validate_args
)
)
if should_append:
actions.append(actions_dist[-1].sample())
actions_logprobs.append(actions_dist[-1].log_prob(actions[i]))
return tuple(actions), torch.stack(actions_logprobs, dim=-1).sum(dim=-1, keepdim=True), values
def get_value(self, obs: Dict[str, Tensor]) -> Tensor:
feat = self.feature_extractor(obs)
return self.critic(feat)
def get_greedy_actions(self, obs: Dict[str, Tensor]) -> Sequence[Tensor]:
feat = self.feature_extractor(obs)
out = self.actor_backbone(feat)
pre_dist: List[Tensor] = [head(out) for head in self.actor_heads]
if self.is_continuous:
# Just take the mean of the distribution
return [torch.chunk(pre_dist[0], 2, -1)[0]]
else:
# Take the mode of the distribution
return tuple(
[
OneHotCategoricalValidateArgs(
logits=logits, validate_args=self.distribution_cfg.validate_args
).mode
for logits in pre_dist
]
)
def build_agent(
fabric: Fabric,
actions_dim: Sequence[int],
is_continuous: bool,
cfg: Dict[str, Any],
obs_space: gymnasium.spaces.Dict,
agent_state: Optional[Dict[str, Tensor]] = None,
) -> _FabricModule:
agent = A2CAgent(
actions_dim=actions_dim,
obs_space=obs_space,
encoder_cfg=cfg.algo.encoder,
actor_cfg=cfg.algo.actor,
critic_cfg=cfg.algo.critic,
mlp_keys=cfg.algo.mlp_keys.encoder,
distribution_cfg=cfg.distribution,
is_continuous=is_continuous,
)
if agent_state:
agent.load_state_dict(agent_state)
agent = fabric.setup_module(agent)
return agent
For simplicity we have only defined the MLPEncoder and A2CAgent classes, which are the ones we will use in this article. The MLPEncoder class is used to create a multi-layer perceptron (MLP) encoder, which is used to extract features from the observations. The A2CAgent class is used to create the agent model, which is composed by:
- A feature extractor, which is an MLP encoder that takes as input the observations and outputs a vector of features
- A critic, which is an MLP that takes as input the features extracted by the feature extractor and outputs a value $V(s_t)$, which is an estimate of the expected return if the agent starts in state $s_t$ and follows the policy $\pi$ afterwards
- An actor, which is an MLP that takes as input the features extracted by the feature extractor and outputs a probability distribution over the possible actions $a_t$
3. loss.py
The third thing is the loss.py file, where we will define all the loss functions’, which will be used to compute the loss.
There are two loss functions we need to define:
-
The policy loss, which is used to train the actor and is defined as:
\[L_{\pi} = -\sum_{t=1}^{T} \log \pi_{\theta}(a_t \vert s_t)[G_t - V_{\theta}^{\pi}(s_t)] = -\sum_{t=1}^{T} \log \pi_{\theta}(a_t \vert s_t) A_t\]where $A_t$ is the advantage function, which is defined as:
\[A_t = G_t - V_{\theta}^{\pi}(s_t)\]where $G_t$ is the return at time $t$, which is defined as:
\[G_t = \sum_{k=t}^{T} \gamma^{k-t} R_{k+1}\]The advantage indicates how much better an action is given a particular state over a random action selected according to the policy for that state.
-
The value loss, which is used to train the critic and is simply the Mean Squared Error (MSE) between the estimated value and the actual return:
\[L_{V} = \sum_{t=1}^{T} (G_t - V_{\theta}^{\pi}(s_t))^2\]
# loss.py
import torch.nn.functional as F
from torch import Tensor
def policy_loss(
logprobs: Tensor,
advantages: Tensor,
reduction: str = "mean",
) -> Tensor:
"""Compute the policy loss for a batch of data, as described in equation (7) of the paper.
- Compute the difference between the new and old logprobs.
- Exponentiate it to find the ratio.
- Use the ratio and advantages to compute the loss as per equation (7).
Args:
logprobs (Tensor): the log-probs of the sampled actions from the environment.
advantages (Tensor): the advantages.
Returns:
the policy loss
"""
pg_loss = -(logprobs * advantages)
reduction = reduction.lower()
if reduction == "none":
return pg_loss
elif reduction == "mean":
return pg_loss.mean()
elif reduction == "sum":
return pg_loss.sum()
else:
raise ValueError(f"Unrecognized reduction: {reduction}")
def value_loss(
values: Tensor,
returns: Tensor,
reduction: str = "mean",
) -> Tensor:
return F.mse_loss(values, returns, reduction=reduction)
4. utils.py
The fourth and almost last thing is the utils.py file, where we will define all the utility functions, which will be used to train the agent:
# utils.py
from typing import Any, Dict
import torch
from lightning import Fabric
from sheeprl.algos.a2c.agent import A2CAgent
from sheeprl.utils.env import make_env
AGGREGATOR_KEYS = {"Rewards/rew_avg", "Game/ep_len_avg", "Loss/value_loss", "Loss/policy_loss"}
@torch.no_grad()
def test(agent: A2CAgent, fabric: Fabric, cfg: Dict[str, Any], log_dir: str):
env = make_env(cfg, None, 0, log_dir, "test", vector_env_idx=0)()
agent.eval()
done = False
cumulative_rew = 0
o = env.reset(seed=cfg.seed)[0]
obs = {}
for k in o.keys():
if k in cfg.algo.mlp_keys.encoder:
torch_obs = torch.from_numpy(o[k]).to(fabric.device).unsqueeze(0)
torch_obs = torch_obs.float()
obs[k] = torch_obs
while not done:
# Act greedly through the environment
if agent.is_continuous:
actions = torch.cat(agent.get_greedy_actions(obs), dim=-1)
else:
actions = torch.cat([act.argmax(dim=-1) for act in agent.get_greedy_actions(obs)], dim=-1)
# Single environment step
o, reward, done, truncated, _ = env.step(actions.cpu().numpy().reshape(env.action_space.shape))
done = done or truncated
cumulative_rew += reward
obs = {}
for k in o.keys():
if k in cfg.algo.mlp_keys.encoder:
torch_obs = torch.from_numpy(o[k]).to(fabric.device).unsqueeze(0)
torch_obs = torch_obs.float()
obs[k] = torch_obs
if cfg.dry_run:
done = True
fabric.print("Test - Reward:", cumulative_rew)
if cfg.metric.log_level > 0:
fabric.log_dict({"Test/cumulative_reward": cumulative_rew}, 0)
env.close()
In particular we have defined the test function, which is used to test the agent in the environment.
5. Configs
One of the almost last thing we need to do is to define the configuration files, which will be used to configure the agent and the default experiment. We advise to have a look at our how-to regarding SheepRL configs.
We first create the config folder, then we define the following configuration files:
- configs/algo/a2c.yaml: the algorithm’s configuration, which will be used to configure the agent
- configs/exp/a2c.yaml: the default experiment configuration file
defaults:
- default
- /optim@optimizer: adam
- _self_
# Training receipe
name: a2c
gamma: 0.99
gae_lambda: 1.0
loss_reduction: mean
rollout_steps: 16
dense_act: torch.nn.Tanh
max_grad_norm: 100
# Encoder
encoder:
mlp_layers: 1
dense_units: 64
mlp_features_dim: 64
dense_act: ${algo.dense_act}
# Actor
actor:
mlp_layers: 2
dense_units: 64
dense_act: ${algo.dense_act}
# Critic
critic:
mlp_layers: 2
dense_units: 64
dense_act: ${algo.dense_act}
# Single optimizer for both actor and critic
optimizer:
lr: 1e-3
eps: 1e-4
# @package _global_
defaults:
- override /algo: a2c
- override /env: gym
- _self_
# Algorithm
algo:
total_steps: 25000
rollout_steps: 5
per_rank_batch_size: ${algo.rollout_steps}
mlp_keys:
encoder: [state]
# Buffer
buffer:
share_data: False
size: ${algo.rollout_steps}
metric:
aggregator:
metrics:
Loss/value_loss:
_target_: torchmetrics.MeanMetric
sync_on_compute: ${metric.sync_on_compute}
Loss/policy_loss:
_target_: torchmetrics.MeanMetric
sync_on_compute: ${metric.sync_on_compute}
6. Algorithm and configs registration
To let SheepRL know about our new algorithm we need to register it. To do so we need to add a new file, which will act as our entrypoint, called (for example) a2c_main.py at the root our project:
# a2c_main.py
# This will trigger the algorithm registration of SheepRL
from a2c import a2c # noqa: F401
if __name__ == "__main__":
# This must be imported after the algorithm registration, otherwise SheepRL
# will not be able to find the new algorithm given the name specified
# in the `algo.name` field of the `./my_awesome_configs/algo/ext_sota.yaml` config file
from sheeprl.cli import run
run()
To let SheepRL know about our new configuration files we need to add a new file, called (for example) .env at the root our project with the following env variable in it:
SHEEPRL_SEARCH_PATH=file://configs;pkg://sheeprl.configs
7. Run the experiment
In the end you should have the following project structure:
.
├── .env
├── a2c
│ ├── a2c.py
│ ├── agent.py
│ ├── __init__.py
│ ├── loss.py
│ └── utils.py
├── a2c_main.py
└── configs
├── algo
│ └── a2c.yaml
└── exp
└── a2c.yaml
To run the experiment we need to simply execute the following command:
python a2c_main.py exp=a2c env.num_envs=4
This will run the experiment using the default configuration file, which is configs/exp/a2c.yaml; you can follow the experiment progress with TensorBoard by running the following command:
tensorboard --logdir <log_dir>
where log_dir is the directory where the logs are saved, which is printed in the terminal when the experiment starts.
Conclusion
In this article we have seen how to implement the A2C algorithm in SheepRL. In particular, we have seen how to define the algorithm, starting from the register-new-algorithm how-to, the agent by taking inspiration from the PPO one, the loss functions, the utility functions, and the configuration files. We have also seen how to register the algorithm and how to run the experiment. We hope you have enjoyed this article and we hope to see you in the next one!