SAC-AutoEncoder
SAC-AutoEncoder: End-to-End Reinforcement Learning from images
In our last blogpost we introduced the Proximal Policy Optimization (PPO) algorithm, which combines the Actor-Critic with a surrogate objective to mitigate the risk of overly disruptive policy updates. In this blogpost we will introduce the Soft Actor Critic algorithm and how to adapt it to learn directly from images.
Thanks to its versatility and sample efficiency SAC has been long used to model agents acting in the continuous domain, culminating in its breakthrough adaptation in the Gran Turismo 7 videogame, where the agent was able to reach superhuman performances against human world champions.
The Soft Actor Critic
Differently from PPO, SAC is an off-policy algorithm, meaning that it can reuse past experiences to improve the policy used to take action in the envrionment. At its core, SAC uses a technique called maximum entropy objective, which encourages exploration by adding an entropy term to the reward function to be maximized. This entropy term promotes the agent to take actions that have more uncertainty, leading to more diverse exploration and potentially discovering better strategies.
\[J(\pi) = \sum_{t=0}^{T}\mathbb{E}_{(s_t,a_t)\sim\rho_{\pi}}[r(s_t,a_t) + \alpha \mathcal{H}(\pi(\cdot \vert s_t))]\]To learn the optimal maximum entropy policy SAC alternates between the policy evaluation and policy improvement steps in the maximum entropy framework defined above.
During the policy evaluation step SAC uses the concept of soft value function, which is a modification of the traditional value function where the additional entropy term is incorporated to measure the uncertainty in the agent’s policy.
\[V(s_t) = \mathbb{E}_{a_t\sim\pi}[Q(s_t, a_t) - \log\pi(a_t \vert s_t)]\]By adding the entropy term to the value function, SAC encourages the agent to explore a wider range of actions and avoid getting stuck in suboptimal or repetitive behavior.
During the policy improvement step instead, SAC updates the policy towards an exponential distribution of the new Q-function, where, to maintain the its tractability, the policy is searched between Gaussian distributions.
\[\pi_{\text{new}}=\text{arg min}_{\pi'\in \Pi} \text{KL}\left(\pi'(\cdot \vert s_t) \vert \vert \exp{(Q^{\pi_{\text{old}}}(s_t, \cdot))}\right)\]Learning from images
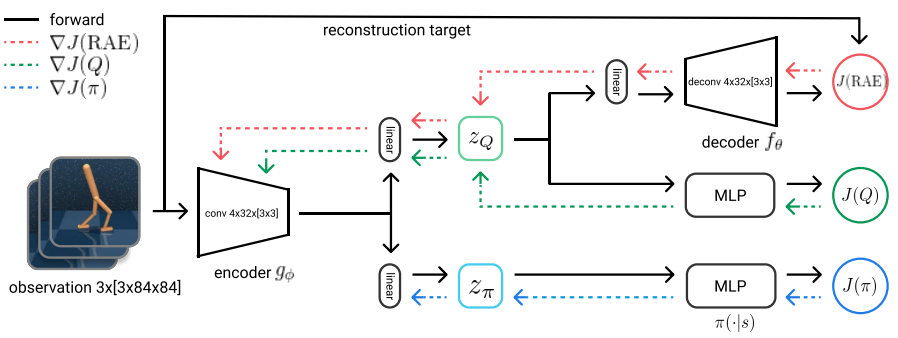
Images are everywhere, thus having effective RL approaches that can utilize pixels as input would potentially enable solutions for a wide range of real world applications, for example robotics and videogames. In SAC-AutoEncoder the standard SAC agent is enriched with a convolutional encoder, which encodes images into features, shared between the actor and critic. Also, to improve the quality of the extracted features, a convolutional decoder is used to reconstruct the input images from the features, effectively creating the Encoder-Decoder architecture.
But…
learning from images can be cumbersome without taking into account the right tricks. Three of them being the following:
- Deterministic autoencoder: the encoder-decoder architecture is a deterministic one, which means that we are not going to learn a distribution over the extracted features conditioned on the input images
- The encoder will receive the gradients from the critic but not from the actor: receiving the gradients from the actor changes also the Q-function, since the encoder is shared between the actor and the critic
- To overcame the slowdown in the encoder update due to 2., the convolutional weights of the target Q-function are updated faster than the rest of the network’s parameters
Conclusion
In conclusion, SAC-AutoEncoder has proved as a powerful and versatile tool in Reinforcement Learning to learn directly from raw pixels. Its ability to reuse past experiences while combining some simple but effective tricks has propelled SAC-AutoEncoder to the forefront of image-based RL applications.
Do you want to know more about how we implemented SAC-AE? Check out our implementation.