Unleashing the Power of PPO
In the rapidly evolving realm of Reinforcement Learning (RL), one algorithm has emerged as a true game-changer - the Proximal Policy Optimization (PPO) algorithm.
PPO’s versatility and impressive track record since its introduction in 2017 have led to numerous successful applications across various domains, from the renowned OpenAI Five project to the recent advancements in ChatGPT. In this blog post, we delve into the captivating world of PPO, exploring its strengths, simplicity, and how it has revolutionized the field of RL.
PPO: A Versatile and Powerful Policy Gradient Algorithm
PPO, at its core, is a policy gradient algorithm that learns a policy directly. Moreover, PPO is an on-policy algorithm, meaning it learns from the data it collects while actively interacting with the environment. This characteristic sets the foundation for PPO’s unique capabilities and applications.
Actor-Critic Architecture for Enhanced Learning
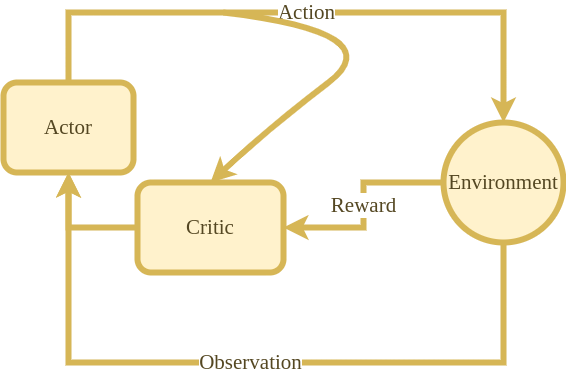
PPO belongs to the actor-critic family of algorithms, where it simultaneously learns a policy (actor) and a value function (critic). The policy is responsible for selecting actions, while the value function evaluates the quality of the chosen actions. This combined approach enables PPO to learn and improve both the decision-making process and the assessment of action outcomes, resulting in more refined policies.
The Surrogate Objective Function: Unlocking Optimization Potential
PPO’s main strength lies in its utilization of a surrogate objective function, which serves as a lower bound approximation of the original objective function. The original objective function, representing the expected value of rewards collected by the agent, is challenging to optimize directly. By using the surrogate objective function, PPO simplifies the optimization process and enhances learning efficiency.
Advantage Function and Probability Ratio: Key Components of PPO
The surrogate objective function comprises two essential components: the advantage function and the probability ratio. The advantage function calculates the difference between the sum of rewards collected by the agent and the value function’s estimation of expected rewards. The probability ratio compares the likelihood of taking an action under the new policy to that under the old policy.
Stability through Clipping: Balancing Exploration and Exploitation
To maintain stability and prevent drastic policy changes, the probability ratio is clipped between $1-\epsilon$ and $1+\epsilon$, where $\epsilon$ is a hyperparameter. This ensures a controlled balance between exploration and exploitation, mitigating the risk of overly disruptive policy updates.
In conclusion, PPO has emerged as a powerful and versatile tool in Reinforcement Learning. Its ability to learn directly from on-policy data, combined with its actor-critic architecture and the use of a surrogate objective function, has propelled PPO to the forefront of RL applications. Whether it’s training intelligent agents to play complex games, fine-tuning language models, or enhancing customer experiences, PPO continues to push the boundaries of what is possible in the realm of AI. As the field evolves, the fascinating potential of PPO promises to shape the future of Reinforcement Learning and revolutionize how we interact with intelligent systems.
Do you want to know more about how we implemented PPO? Check out this post in Lightning’s blog from our researcher Federico