From 0 to RL with SheepRL
SheepRL: an overview
In the rapidly evolving landscape of artificial intelligence and machine learning, SheepRL has emerged as a flexible alternative in the realm of Reinforcement Learning (RL) frameworks, demonstrating remarkable growth and adaptability across various dimensions.
One of the standout features of SheepRL is its versatility in handling different types of actions. Whether it’s discrete, multi-discrete, or continuous actions, SheepRL is designed to support them all. This flexibility empowers developers to tackle a wide range of RL problems, making it a valuable tool for researchers and practitioners alike.
What truly sets SheepRL apart is its commitment to staying at the cutting edge of RL algorithms. The inclusion of state-of-the-art algorithms like Dreamer-V3, demonstrates SheepRL’s dedication to providing users with the most advanced and effective tools available in the field. Dreamer-V3, in particular, showcases the framework’s capability to simulate and learn from imagined experiences, a feature that opens up exciting possibilities for training RL agents.
SheepRL’s fully distributed nature, made possible by Lightning Fabric, ensures that RL practitioners can harness the power of distributed computing seamlessly. This distributed approach enables more efficient training of RL models, making it suitable for tackling complex real-world problems that demand substantial computational resources.
Moreover, SheepRL’s adaptability is further enhanced by its integration with Hydra. This integration simplifies the process of configuring and customizing RL experiments, making it user-friendly and accessible to a wide range of developers, from beginners to experts. The framework’s emphasis on clarity and ease of use is a testament to its commitment to fostering a welcoming and productive RL development environment.
Dreamer-V3 beats them all!
To demonstrate the power and the flexibility offered by our framework we have run experiments with different environments and a single algorithm, namely Dreamer-V3, with a single set of hyperparameters for every environment.
Diambra
Diambra is a competition platform that allows you to submit your agents and compete with other coders around the globe in epic video games tournaments! Featuring a collection of high-quality environments for Reinforcement Learning research and experimentation, it provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
We have trained a Dreamer-V3 agent in the Dead or Alive++ environment obtaining the best score in the global leaderboard. Moreover, by looking at the actions’ distribution, we have noted that the agent was able to win the game in the hardest difficulty by simply standing down and throwing kicks. This can be an useful insight for the developers, indicating that the game’s dynamic can be improved.


Minecraft
Minecraft is a 3D, first-person, open-world game centered around the gathering of resources and creation of structures and items. It can be played in a single-player mode or a multi-player mode, where all players exist in and affect the same world. Games are played across many sessions, for tens of hours total, per player. Notably, the procedurally generated world is composed of discrete blocks which allow modification; over the course of gameplay, players change their surroundings by gathering resources (such as wood from trees) and constructing structures (such as shelter and storage).
As an open-world game, Minecraft has no single definable objective. Instead, players develop their own subgoals which form a multitude of natural hierarchies. Though these hierarchies can be exploited, their size and complexity contribute to Minecraft’s inherent difficulty. One such hierarchy is that of item collection: for a large number of objectives in Minecraft, players must create specific tools, materials, and items which require the collection of a strict set of requisite items. The aggregate of these dependencies forms a large-scale task hierarchy.
In addition to obtaining items, implicit hierarchies emerge through other aspects of gameplay. For example, players (1) construct structures to provide safety for themselves and their stored resources from naturally occurring enemies and (2) explore the world in search of natural resources, often engaging in combat with non-player characters. Both of these gameplay elements have long time horizons and exhibit flexible hierarchies due to situation dependent requirements (such as farming a certain resource necessary to survive, enabling exploration to then gather another resource, and so on).
We have trained a Dreamer-V3 agent in the navigate task of MineRL-v0.4.4, where the agent must move to a goal location denoted by a diamond block. The guidance comes from a “compass” observation, which points near the goal location, 64 meters from the start location. The goal has a small random horizontal offset from the compass location and may be slightly below surface level.
Crafter
Crafter is an open world survival game for reinforcement learning research which features randomly generated 2D worlds with forests, lakes, mountains, and caves. The player needs to forage for food and water, find shelter to sleep, defend against monsters, collect materials, and build tools. The game mechanics are inspired by the popular game Minecraft and were simplified and optimized for research productivity.
A unique world is generated for every episode, leveraging an underlying grid of 64 × 64 cells where the agent only observes the world through pixel images. The terrain features grasslands, lakes, and mountains. Lakes can have shores, grasslands can have forests, and mountains can have caves, ores, and lava.
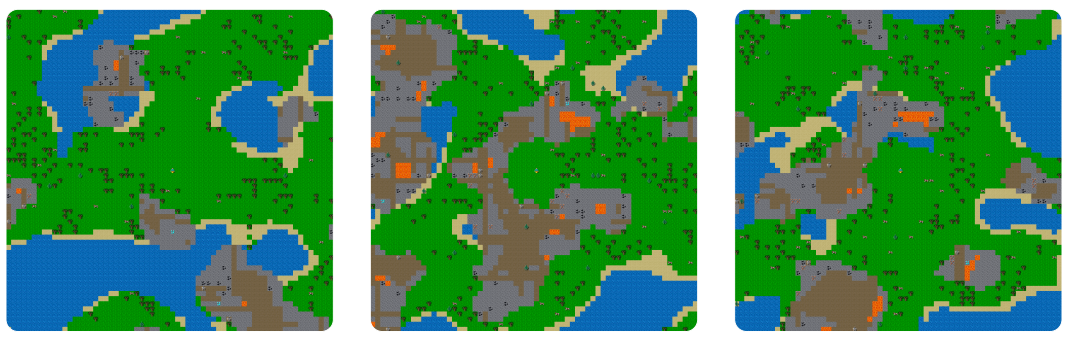
The player has levels of health, food, water, and rest that it must prevent from reaching zero. The levels for food, water, and rest decrease over time and are restored by drinking from a lake, chasing cows or growing fruits to eat, and sleeping in places where monsters cannot attack. Once one of the three levels reaches zero, the player starts losing health points. It can also lose health points when attacked by monsters. When the health points reach zero, the player dies. Health points regenerate over time when the player is not hungry, thirsty, or sleepy.
There are many resources, such as saplings, wood, stone, coal, iron, and diamonds, the player can collect in its inventory and use to build tools and place objects in the world. Many of the resources require tools that the agent must first build from more basic resources, leading to a technology tree with several levels. Standing nearby a table enables the player to craft wood pickaxes and swords, as well as stone pickaxes and stone swords. Crafting a furnace from stone enables crafting iron pickaxes and iron swords from both iron, coal, and wood.
Creatures are initialized in random locations and move randomly. Zombies and cows live in grasslands and are automatically spawned and despawned to ensure a given amount of creatures. At night, the agent’s view is restricted and noisy and a larger number of zombies is spawned. This makes it difficult to survive without securing a shelter, such as a cave. Skeletons live in caves and try to keep the player at a distance to shoot arrows at the player. The player can interact with creatures to decrease their health points. Cows move randomly and offer a food source.
Our trained Dreamer-V3, trained with a budget of 1M steps in the environment with the same hyperparameters of the previous two experiments, was able to collect a lot of achievements and to survive through the night.


Conclusion
In summary, SheepRL represents a promising addition to the ever-growing landscape of RL frameworks. Its support for diverse action spaces, dedication to staying at the forefront of applied RL, distributed capabilities through Lightning Fabric, and user-friendly design via Hydra make it an exciting choice for researchers and developers seeking to harness the potential of reinforcement learning. Moreover, our Dreamer-V3 implementation can be employed to learn agents in a moltitude of different environments with no hyperparameters tuning, reducing the overall time of experimentations while being perfectly aligned with the original one.